
Opened 10 years ago
Closed 13 months ago
#364 closed Bug / Defect (fixed)
UDP over IPv6 packet fragementation calculation error.
| Reported by: | john7000 | Owned by: | Gert Döring |
|---|---|---|---|
| Priority: | major | Milestone: | release 2.6 |
| Component: | Generic / unclassified | Version: | OpenVPN 2.3.2 (Community Ed) |
| Severity: | Not set (select this one, unless your'e a OpenVPN developer) | Keywords: | UDP IPv6 Fragmentation |
| Cc: |
Description
It seems that openVPN 2.3.2 fragmentation calculations when using UDP over IPv6 transport are incorrect resulting in oversize packets being passed to the network stack for transmission (initially mentioned in a comment added to bug #348). The problem does not occur when tunnel transport is using UDP over IPv4 on the same equipment and path. The effect of the fragmentation error is to break the tunnel connection when a graphic item is transferred or similar large size packet demand occurs.
It appears that OpenVPN generates oversize UDP packets and passes these to the network stack. The network stack will then attempt further fragmentation but the fragment uses IPv6 extension headers and these are administratively blocked by intervening firewalls which in turn issue ICMPv6 unreachable code 1 (administratively prohibited) messages.
In my tests the issue was observed using
- Tunnelled HTTP over TCP over IPv4 (client 192.168.1.132 and web server 192.168.1.1)
- Transport on UDP over IPv6 (client 2001:db8:0:2:<private temporary address> and VPN server 2001:db8:0:1:102:304:506:708)
The results described below were generated on the following equipment and network infrastructure. The IPv6 addresses have been anonymised by directly editing (with Hex Fiend) the PCAP files. The addresses listed below match the modified capture file snippets as displayed by Wireshark (screen captures attached) of the modified PCAP files.
OpenVPN Client - Windows 7 VM running openVPN 2.3.2 (hosted on MacBook? Pro using VMware Fusion with the network in bridged mode)
- wired ethernet interface address 2001:db8:0:2:<privacy address>
- tunnel address 192.168.6.132
OpenVPN server - Centos 6.3 running openVPN 2.3.2 with 'multihome' declared
- wired ethernet address used for tunnel end point 2001:db8:0:1:102:304:506:708
- single dual stack physical ethernet connection (eth0)
- eth0 MTU configured to 1492 (for PPPoE ADSL operation)
- tcpdump used to capture traffic on eth0 and then filtrered to remove unrelated traffic.
Web server - Ubuntu running Apache and MRTG (used to generate graphical output in the form of PNG files)
- wired ethernet address 192.168.1.1
- eth0 MTU configured to 1492 (for PPPoE ADSL operation)
Web server and OpenVPN server are connected at 1Gbps through an unmanaged switch. It appears that some frames from the web server are jumbo frames exceeding 1500 octets even though the interfaces are configured to 1492.
The connection between the client and the openVPN server is via an ISP offering native IPv6 (dual stack). The client and server are on different ADSL services. One uses PPPoE and the other PPPoA. PPPoE reduces the MTU to 1492. Cisco routers are used on both services at the client and server ends and these are configured to allow ICMPv6 unreachable messages to support PMTUD. Only one ISP exchange/central station is traversed but this appears to be using a Cisco ASA 5500 series firewall or similar features in their router(s). It has been observed that sequence number randomisation is being applied by the ISP to IPv6 in both directions (a default feature of the Cisco ASA and some other firewalls and ISP CE routers). The address of the device issuing the ICMPv6 unreachable messages has been partially anonymised by replacing the top 64bits with 2001:db8:0:3
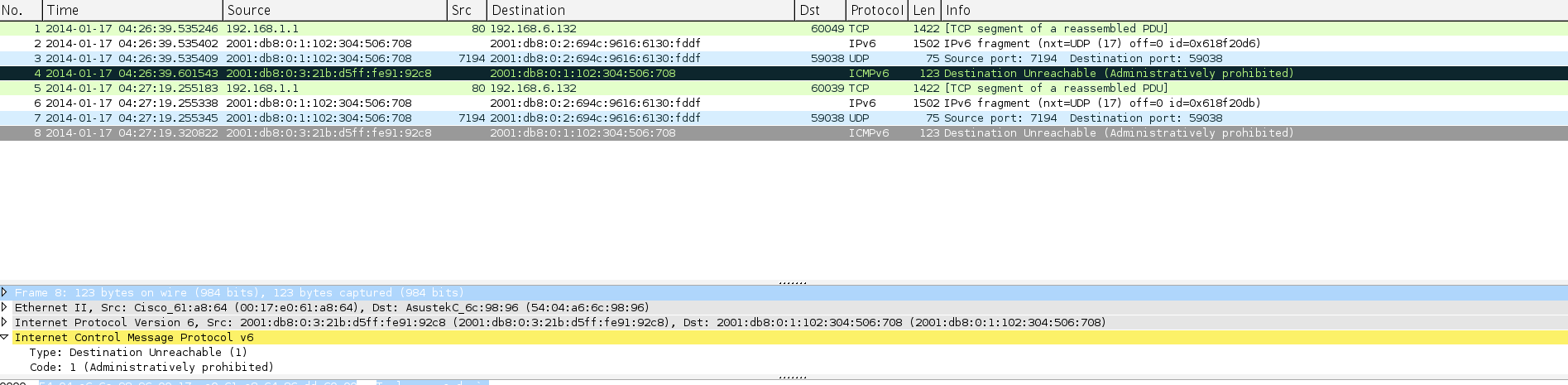
What we see in the samples is that an HTTP request has caused the server (192.168.1.1) to send to the browser (192.168.6.132) a large frame. In sample 1 see line nos 8 and 26 and sample 2 lines 1 and 5 which are received by the OpenVPN server.
OpenVPN proceeds to encrypt the complete HTTP/TCP/IPv4 packet This will be passed to the stack using sendmsg() or sendto() function which will then complete the transport envelope resulting in the packets sent from 2001:db8:0:1… (server) to 2001:db8:0:2… (client). What we see is two or more fragments. In Sample 1 we see 10,11,12,13,14,16 and 27,28,29,30. In Sample 2 we see 2,3 and 6,7. In each case one of these messages has and IPv6 UDP extension header and Wireshark reports this as an IPv6 fragment.
The ISP router is disallowing the extension headers as per standard security and performance recommendations. Fragments can not be validated until they are reassembled and reassembly opens the door for DoS-ing of the firewall besides adding latency. So as a result the ISP device sends back an ICMPv6 unreachable with code administratively prohibited (source 2001:db8:0:3…). This can be seen in Sample 1 at 17 (ICMPv6 rate limit may be blocking the second message). Sample 2 shows this at 4 and 8.
The OpenVPN code appears not to be including in the calculation the additional 20 octets required when the transport protocol is IPv6 rather than IPv4 and thus fragmentation at the stack level is running into the security protection imposed by the ISP.
Attachments (2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (10)
Changed 10 years ago by
| Attachment: | UDP fragmentation sample 1.png added |
|---|
Changed 10 years ago by
| Attachment: | UDP fragmentation sample 2.png added |
|---|
comment:1 Changed 9 years ago by
| Owner: | set to Gert Döring |
|---|---|
| Status: | new → assigned |
comment:2 Changed 9 years ago by
| Milestone: | → release 2.5 |
|---|
comment:3 Changed 9 years ago by
| Milestone: | release 2.5 → release 2.4 |
|---|
comment:4 Changed 9 years ago by
comment:5 Changed 8 years ago by
Yes the problem still exists in OpenVPN 2.3.8. I have just re-tested using a Centos 6.7 server and Tunnelblick on MacOSX client transporting TCP/IPv4 over UDP/IPv6 transport.
When TCP payload packets of large enough size are encrypted OpenVPN generates oversize UDP transport packets. The sending network stack then performs IPv6 fragmentation resulting in two packets - one containing an IPv6 fragment header with the majority of the encrypted payload data followed by a smaller packet containing the actual UDP header and remaining encrypted payload.
Whilst the network may transport this successfully and the receiver reform the oversize packet on receipt (which does work correctly) it is not uncommon for intermediate firewalls or packet filters to be configured to drop IPv6 fragments for at least these reasons
- The firewall must store in memory the fragments whilst it awaits the complete set so that it can perform layer 4 filtering or deeper packet inspection. This provides an opportunity for a DoS attack by crafting many fragments leading to memory exhaustion in the firewall/filter.
- The firewall cannot perform simple layer 4 port filtering on the fragments that do not contain the UDP header.
- It is unlikely that fragment handling can be performed in dedicated hardware so must be software switched leading to poor throughput performance.
The issue may not occur in some circumstances and I am still testing some of these. For example a Windows 7 client appears not to behave the same way. That test client is currently using OpenVPN 2.3.2 but the difference could be the behaviour of the Windows IPv6 network stack with several possibilties
- Negotiation of the TCP MSS or IP MTU resulting in smaller payload packets and thus not triggering the oversize UDP transport packets (unlikely reason)
- Other different TCP settings such as timing or SACK
- HTTP (test protocol) settings from the Windows browser
- Different flow control algorithms and congestion detection mechansisms between Windows, MacOSX and Linux network stacks.
Whichever way the problem is experienced the fundamental issue is that the OpenVPN pre-encryption fragment size calculations used for UDP transport packets over IPv6 is wrong (20 bytes too big) leading to oversize UDP packets. The sending network stack then deals with these instead but in a manner which conflicts with robust network security filtering.
BTW Oversize DNS/UDP/IPv6 can also lead to IPv6 fragmentation and then get blocked by filters - but DNS has other fallbacks e.g. to TCP/IPv6 or to UDP/IPv4 so this may never be noticed.
comment:6 Changed 8 years ago by
OSX Mavericks network stack appears to be inserting a 12 byte TCP option header containing Time stamps. This 12 bytes may be missing from the fragment size calculation. Windows 7 does not do this
comment:7 Changed 8 years ago by
After a lot of tests and then searching of the 2.3.8 source I think I have found two issues leading to this problem.
- forward.c does not call frame_adjust_path_mtu() within check_fragment_dowork() for an IPV6 tunnel due to this -- if (lsi->mtu_changed && c->c2.ipv4_tun)
- Even if it did call frame_adjust_path_mtu() the answer would be wrong (though in a direction which leads only to inefficiencies.
The enum proto_num in socket.h lists 1x UDPv4 (val 1), 3x TCPv4 (vals 2,3,4), 1x UDPv6 (val 5) and 3x TCPv6 (vals 6,7,8). The array proto_overhead has only TWO TCPv4 headers (2 and 3). Consequently UDPv6 would get the header size 60 and not 48 which is bigger than it needs to be. There are also negative effects for PROTO_TCPv6_SERVER but this will be dealt with inefficiencies elsewhere.
I have not had the opportunity to test the code with both of these changed or debug lines added.
In socket.h (2.3.8) we find this
/*
- Use enum's instead of #define to allow for easier
- optional proto support */
enum proto_num {
PROTO_NONE, /* catch for uninitialized */
PROTO_UDPv4,
PROTO_TCPv4_SERVER,
PROTO_TCPv4_CLIENT,
PROTO_TCPv4,
PROTO_UDPv6,
PROTO_TCPv6_SERVER,
PROTO_TCPv6_CLIENT,
PROTO_TCPv6,
PROTO_N
};
...
/*
- Overhead added to packets by various protocols. */
#define IPv4_UDP_HEADER_SIZE 28
#define IPv4_TCP_HEADER_SIZE 40
#define IPv6_UDP_HEADER_SIZE 48
#define IPv6_TCP_HEADER_SIZE 60
extern const int proto_overhead[];
static inline int
datagram_overhead (int proto)
{
ASSERT (proto >= 0 && proto < PROTO_N);
return proto_overhead [proto];
}
In socket.c (2.3.8) we find this
const int proto_overhead[] = { /* indexed by PROTO_x */
0,
IPv4_UDP_HEADER_SIZE, /* IPv4 */
IPv4_TCP_HEADER_SIZE,
IPv4_TCP_HEADER_SIZE,
IPv6_UDP_HEADER_SIZE, /* IPv6 */
IPv6_TCP_HEADER_SIZE,
IPv6_TCP_HEADER_SIZE,
IPv6_TCP_HEADER_SIZE,
};
comment:8 Changed 13 months ago by
| Milestone: | release 2.4 → release 2.6 |
|---|---|
| Resolution: | → fixed |
| Status: | assigned → closed |
This should now be finally fixed, in 2.6.0 and later.
The whole packet size / packet overhead calculation was wrong in many regards, not taking IPv6 header overhead into account was just one - but "cipher negotiations" could also lead to oversized packets, or to not fully utilizing what is available.
The fixes will not be backported to 2.3 to 2.5 (the 2.3 fix might be straightforward, because "only ipv6 header" is affected, but 2.4/2.5 has the cipher negotiation stuff and the fix set is much larger).
Is this still an issue?